I’m not an AI expert. If you want one of those, I recommend checking out Eliezer Yudkowsky. For the last two decades, he has been warning of the potential threat of AI in very concrete terms. His efforts, including founding the Machine Intelligence Research Institute, have largely been ignored, and we’re now approaching some of the threats he warned about, with no real plan for how to combat them.
All I want to do here is present a low-level primer on why the dangers of AI should be taken seriously. I’m not trying to downplay the benefits. Personally, AI has already had wonderful effects on my learning, especially regarding computer programming. But as great as those are, the threat is even more significant.
If you’re reading this, you’re probably at least vaguely aware of what ChatGPT is. If not, please watch this video before continuing. If you are, you should probably watch it anyway. There’s a lot you may not know, and I’m not planning on writing a 5000-word article here.
Even if there is no further advancement in AI (spoiler: there will be), AI is already changing things. If it were halted here, however, it would be akin to the Internet. It will eliminate some jobs, make some new ones, and modify how many jobs are done, but it would not be an existential risk.
So why assume we’ll make more progress? Specifically, why assume we’ll ever get to AIs that are smarter than human beings? This does not require any particular knowledge of the current state of AI, as a TED talk from six years ago demonstrates.
Harris lays out three assumptions, and that is all it takes for us to end up with superintelligent AI.
- Substrate independence.This is the assumption that intelligence does not have to run on the specific biology we happen to have, that there is nothing inherently unique about our human-style brains that cannot be replicated in another medium, such as silicon. While some people continue to shift the goalposts of what counts as “AI” (a common theme in AI skepticism) and say that what GPT-4 has displayed is not “real” intelligence, the assumption of substrate independence is becoming more and more supported as the field advances.
- Technological progress will continue.While a rapid rise in AI capability is more worrying than a slow rise, the exact rate is not the determining factor in whether we get there. Barring a catastrophe that sets humanity back so far that we can never recover (large asteroid impact, widespread nuclear war, etc.), any amount of progress at all will get us there eventually.
- Humans are not at the theoretical maximum of intelligence.When we think of geniuses, we may think of the large gap between the ordinary person and someone like Albert Einstein or John von Neumann. We may think that’s what it means to be truly intelligent. But why? There is no known physical law that prevents something from being far, far more intelligent still. We could end up creating something that is to von Neumann what von Neumann was to a chicken, rather than to the average person. [The pictures below are from Harris’ video.]
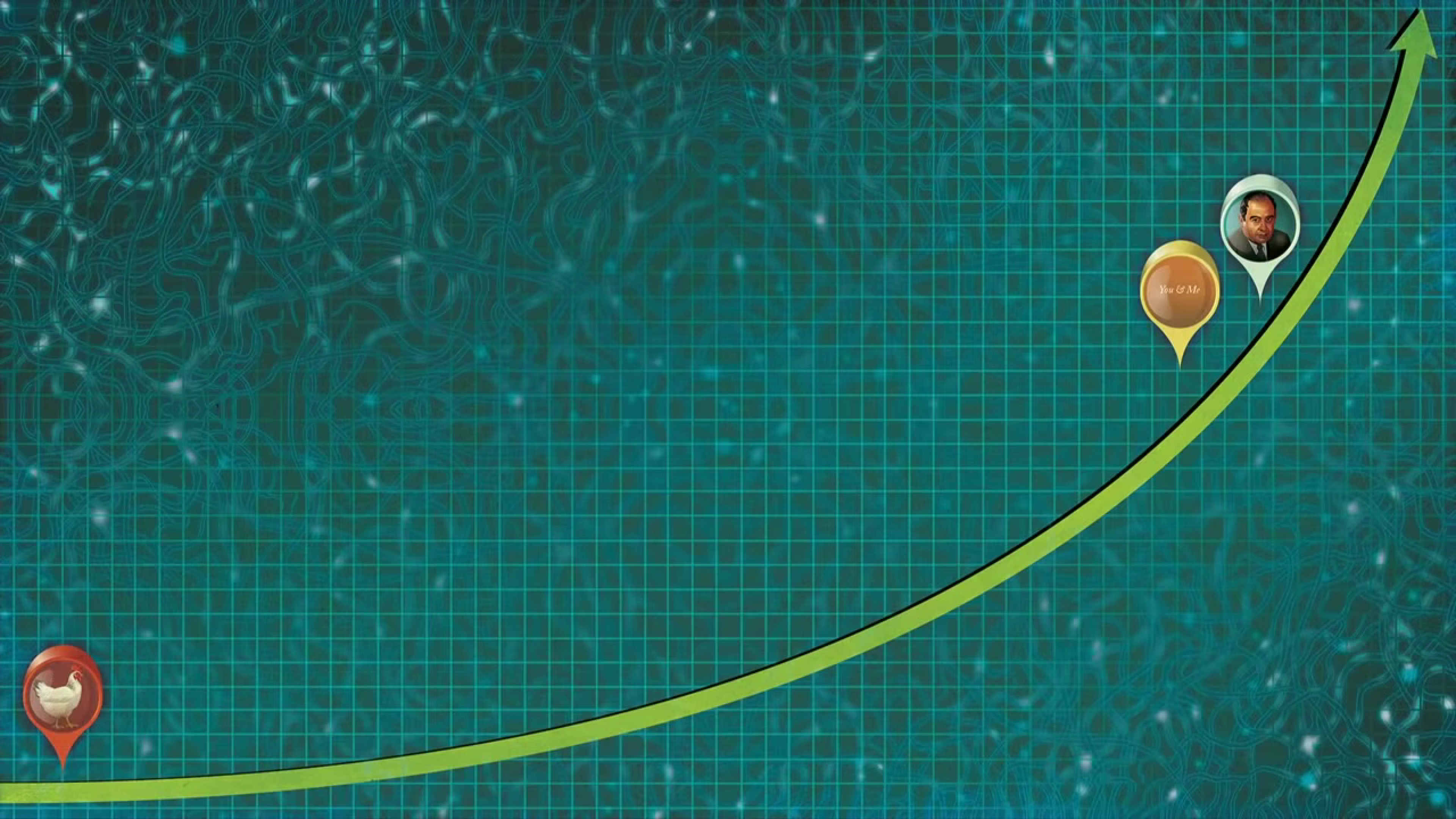

“Well that’s fine! We just have to make sure it wants the same things we want.” I’ve heard many variations of this, and it is what is known as the alignment problem. The main problem is that there are far more ways to get it wrong than to get it right. It’s not enough to think of all the ways a smart human could go wrong and patch them.
Even if the AI in question is not superintelligent, it’s still different. We cannot simply assume that it will have what we refer to as “common sense”. If you tell a sufficiently powerful AI to make you as much money as possible (something that has already been done with GPT-4), you cannot assume it will implicitly add “without massively disrupting the national economy”. We know that’s what we mean. Any sensible person wouldknow that’s what we mean. But you can’t guarantee an AI will know it.
If it is superintelligent, we’re opened up to a far broader array of things that can go wrong. For a light-hearted look at some possible outcomes, let’s play Genocide Bingo:
For a more serious and scholarly (as well as much longer) approach, try “We’re All Gonna Die” with Eliezer Yudkowsky.
“Sure,” optimists say, “we could end up with these bad situations, but aren’t they balanced by the good outcomes AI will bring?” To which I reply, sure, if we hit the bullseye. The problem is, we don’t know how many chances we get, and we’re not sure where on the board the bullseye is, anyway. While I personally believe the bullseye at least exists, even that is not guaranteed by any laws of nature known to us.
GPT-4 is almost certainly not powerful enough by itself to cause any truly massive negative consequences. But will we have any indications before we get one that is? If so, will we have enough warning? Even if we do theoretically have enough time, consider the incentives. If a company is making $10 billion annually with the help of AI, are our social systems set up to prevent that company from forging ahead regardless? They’re not going to want to give up the goose that lays the golden eggs just because there’s a possibility that it will explode and take the world with it next year.
I’m incredibly excited about AI, but I don’t see any strong refutation of Yudkowsky’s claims. There is a decent attempt on LessWrong.com, but the entire thing boils down to the author’s statement “The answer is: don’t reward your AIs for taking bad actions.” In a way, that’s accurate. But defining “bad actions” in the first place is basically solving the alignment problem itself, something we’re nowhere near doing.
It’s certainly possible we make it through this and have a wonderful future. But if we do, we will only be able to attribute it to the same kind of luck that has prevented another nuclear explosion. For those of you who aren’t familiar with nuclear history, consider that the fact that the U.S. once dropped two nuclear bombs on our own country when a B-52 malfunctioned over North Carolina, and a single switch was the only reason they didn’t go off. If you want a longer list, check the Wikipedia page. Yes, there’s an entire page dedicated to how we’ve almost blown ourselves up.
There is obviously far more to AI than I’m presenting here, but I hope I’ve at least helped make you aware of the broad picture. If you have questions or any sub-topics you’d like me to go into in more detail, email me at sean@seanherbison.com.
Further resources:
AI Alignment: Why It’s Hard, and Where to Start – MIRI
Security Mindset and Ordinary Paranoia – LessWrong
Human Compatible – Stuart Russell
Life 3.0: Being Human in the Age of Artificial Intelligence – Max Tegmark
Pausing AI Developments Isn’t Enough. We Need to Shut it All Down – Yudkowsky in TIME
Leave a Reply